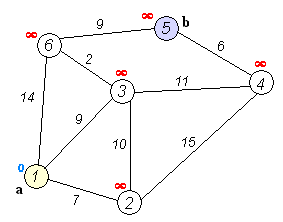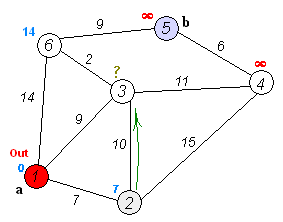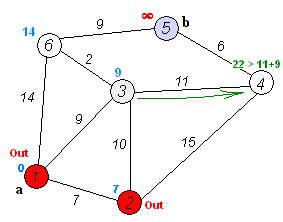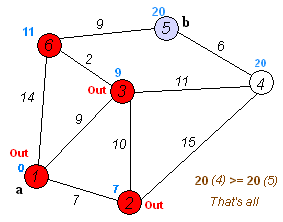
그래프에서 최단 거리를 구할 때 자주 쓰이는 알고리즘이다. 벨만-포드 알고리즘의 장점부터 먼저 알아보자. 1. 거리의 가중치가 음수여도 사용이 가능하다. 2. 음수 사이클 여부의 존재를 알 수 있다. 위의 두 가지만 봐도 벨만포드 알고리즘의 실질적 필요성을 느낄 수 있다. 왜냐면 전에 배운 다익스트라 알고리즘은 음의 가중치가 있으면 사용이 불가능했기 때문이다. 그럼 작동과정을 살펴보자. 작동 과정 1. 시작 노드부터 "노드와 연결된 모든 간선"을 탐방하면서 데이터를 갱신한다. 2. 그 다음 노드와 연결된 모든 간선을 탐방하면서 데이터를 갱신한다. 3. 그 다음 노드의 다음노드와 연결된 모든 간선을 탐방하면서 데이터를 갱신한다. 4. 반복한다. 되게 간단하다. 처음 노드에 연결되어있는 모든 간선을 확인하고..